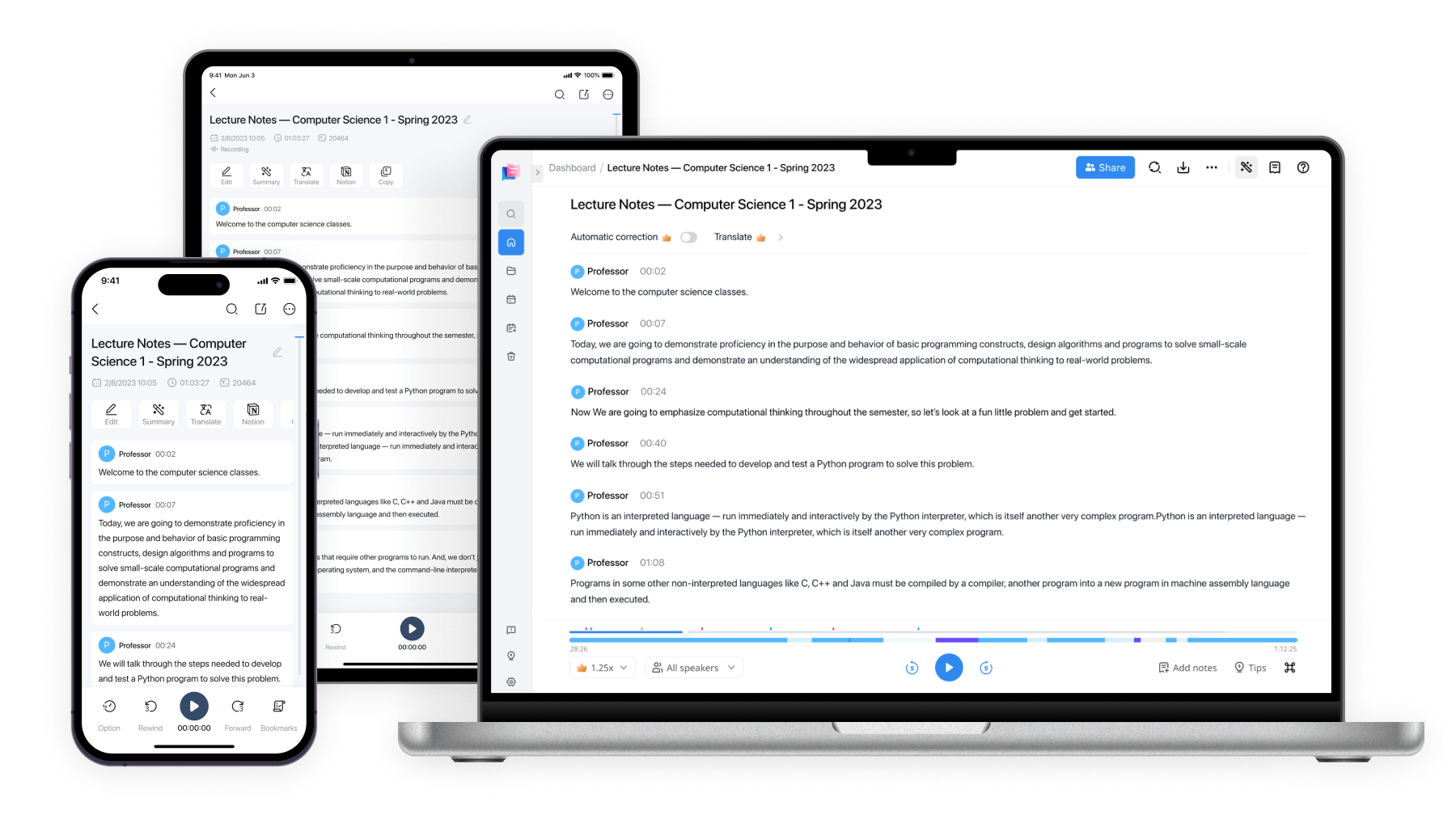
AI Video & Audio Summarizer
Instantly convert media to key notes and transcripts with this free online tool.






Get audio & Video summary in 3 steps

Upload a file to Notta
Choose the audio language for transcription and provide your email address to receive the summary. Click ‘Confirm’ to proceed.

Convert audio to summary
Notta will transcribe your audio or video and automatically generate a summary.

Get summary via email
Once the summary is ready, Notta will send the result to the email address you provided. The link will expire in 72 hours, so please check your inbox promptly.
Why Choose Notta Audio & Video to Text Summarizer
Transcribe Audio and Video
Convert audio and video files into text quickly with high-accuracy transcription technology. Supports up to 58 languages for easy global content conversion.
Generate Summaries Instantly
Automatically generate summaries from transcribed audio and video content in just a few clicks. Leverage multilingual support for global reach.
Share Your Summaries Everywhere
Easily share the generated summaries on websites, social media, and more. Turn podcasts, interviews, and webinars into engaging content that reaches a wider audience.
Frequently Asked Questions
What file formats are supported?
Notta supports the following audio file formats: WAV, MP3, M4A, CAF, AIFF, and the following video file formats: AVI, RMVB, FLV, MP4, MOV, WMV.
What languages are supported for blog generation?
Notta supports 58 languages for audio file transcription. This includes a variety of languages such as Japanese, English, Chinese, Korean, and more.
How are blog articles generated?
Once the transcription is complete, the content is automatically formatted into a blog article. Within seconds, it is converted into an SEO-optimized and engaging article, ready to be posted or shared.
Where can the generated blog article be used?
The generated blog article can be easily shared on websites and social media platforms (Twitter, Facebook, Instagram, etc.). Additionally, it can be directly uploaded to blog platforms like WordPress, making it usable across any media.
What is the accuracy of the transcription?
Notta’s speech recognition has a text conversion accuracy of 98.86%. Additionally, by registering specialized terms in Notta, the accuracy of transcribing sentences containing proper nouns improves, making the speech recognition process more efficient. This feature is available even in the free version.